Explanation
This page provides a web interface so that anyone can easily play around with similarities in word vector models. The 50-dimensional Wikipedia+Gigaword GloVe database is loaded and the user is able to run some operations on it.What are word vectors?
All you really need to know is that word vectors represent words as the location of points in space (in this case, the space has tens or hundreds of dimensions, but you can think of it as 2D or 3D space to visualize the concept). The locations of the words are determined by an algorithm which reads in huge amounts of written text, and looks at nothing other than the context in which words appear. It then tries to adjust the positions of words so that they are close - in the space - to the words that they are actually close to in written language. This turns out to be a very powerful idea - words which appear in the same kinds of sentences will end up grouped together in the space. For instance, "grape" "apple" "pear" "peach" will all end up close to each other, even though the algorithm has no pre-existing knowledge of the concept of "fruit" or what words refer to the names of fruits.
If you want to learn more, Rachael from Rasa gives a nice concise explanation and Dr. Chris Manning from Stanford gives a very in-depth explanation.
Analogy
The GloVe page explains this well. Basically the idea is that the difference between the first two words gets added to the second word, which replicates the effect of the analogy.
Similar
The output shows the fifteen words which are closest in the vector space to the inputted word.
Dissimilar
The output shows the word which is furthest in the vector space from the inputted word. This is not really meaningful in any sense - nor does it say a lot about the inputted word. Some words appear very frequently as outputs from this function, because they are outliers on the edge of the space, far from all of the points.
Opposite
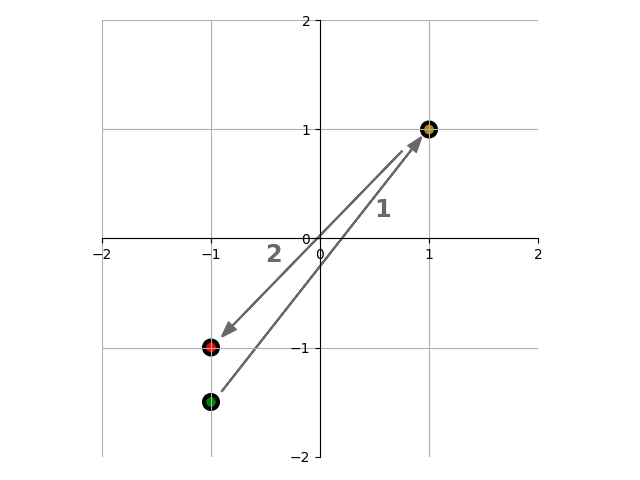
This function takes the inputted word, multiplies its vector representation by -1, and returns the nearest word to that point, in an attempt to find an "opposite" word. It should be noted that it is not a precise opposite, and the operation is not actually an involution. That is, finding the "opposite of the opposite" does not necessarily return the original word.
The reason for this is that the points do not get precisely mirrored, but rather are mirrored and then moved to the location of the nearest word. For example, in the image below there is a very simple example with three points in 2D space. Starting at the green point, the first mirroring operation would return the yellow point, and the next mirroring operation would return the red point.